
Applied deep learning for fruit detection in orchards
Visual inspection is still the most common approach to count fruits and, as such, get an indication of the expected yield. This is an uphill task forcing growers to count fruits only on a limited number of trees over the entire orchard and extrapolate these results. By doing so, farmers don’t have a clear and complete view of the orchards’ health and doubtful yield estimations. They therefore miss the opportunity to understand how and why their yields vary spatially within the orchards.
Deep learning (DL), a subfield of machine learning where algorithms are modelled to imitate human rationale, has recently emerged with highly promising solutions. Nevertheless, there is an applicability gap when applying these algorithms to agriculture, as massive data preparation must be done before exploring DL solutions.
Applied deep learning starts with sufficient training data
Two turning points in the technology era explain the current success of deep learning: an ever-increasing computational capability and data availability. However, a common drawback is a wide variety of environmental conditions intrinsic to agricultural applications, such as variable lighting conditions, phenology, or backgrounds, which challenge deep learning methods. These variable conditions severely impact the operability of such new monitoring tools. This can, to a large extent, be mitigated by collecting many images and labels, including all these conditions.
However, data labelling is a labour-intensive and time-consuming task that requires expert knowledge. Therefore, the main challenge of creating an operational workflow using deep learning in an agricultural setting is obtaining a good training dataset with only a small amount of labelled data.

Image annotation samples from the automatically labelled dataset over the 2020 Canon dataset. The number in the lower right corner indicates the number of fruit annotations.
The magic behind creating large labelled datasets
In our search for an automated on-tree fruit detection algorithm in pear orchards, we had access to thousands of images without any annotation. Thus, using the latest advances in self-supervised deep learning, we created an automatic labelling procedure consisting of two steps: an object discovery algorithm and an object classifier, which helped us annotate thousands of images with minimum human intervention.
-
The object discovery algorithm exploits the segmentation masks that emerge from feature extractors (i.e., Vision Transformers) trained under a self-supervised learning approach to locate objects in the foreground. These feature extractors are openly available. More importantly, they are pre-trained with large-scale datasets containing thousands of object classes, so we can use them to discover the fruits from the orchards’ images without needing any labels.
-
The object classifier exploits the image classification capability of another openly available pre-trained feature extractor, so we can very rapidly use it. The classifier was fine-tuned in a supervised way, so we needed to manually annotate images for this step at a much lower scale (< 2500 annotations).
After less than one day of execution, the outcome of the automatic labelling procedure was a labelled dataset containing more than 100k annotations obtained from more than 40k images. To compare with the manual labelling, on average, we could manually annotate 500 images on an 8-hour workday. With the automatic labelling procedure, we created an extensive training dataset thanks to a small one.
Deep learning models for on-tree fruit detection
A two-stage training approach was chosen, where we first pre-trained the deep learning models with the big labelled dataset and subsequently fine-tuned them with the small dataset. In doing so, we managed to train deep learning models that yielded competitive performance for on-tree fruit detection in pear orchards despite the insufficient manual training data.
Furthermore, besides streamlining the application of a deep learning based solution for on-tree fruit detection, the automatic labelling procedure and training approach can serve many other applications since their implementation is domain-independent. This brings us one step closer to the solution of the big labelled data problem for applied deep learning, which will soon result in more researchers and practitioners harnessing the full potential of these promising solutions.
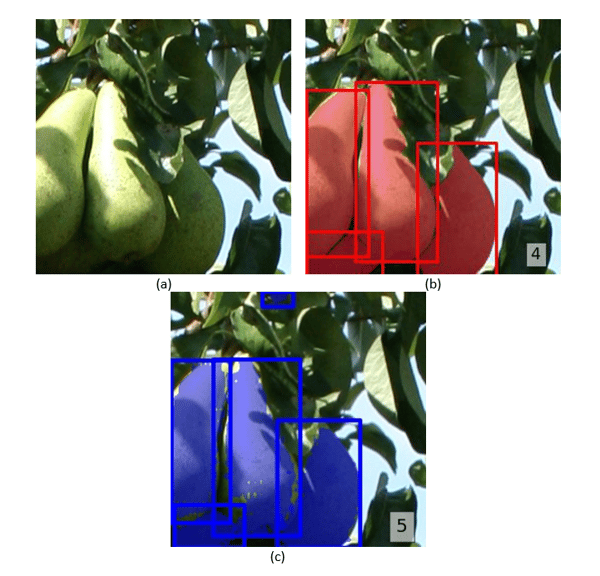
Fruit detections and segmentations from image sample: (a) original image with four pears, (b) with manually annotated fruits, and (c) predictions made by deep learning model. The number of fruit annotations or detections is in the lower right corner.
Next steps for deploying an operational tool in the orchards
An end-to-end automated fruit yield estimation solution can support fruit growers in better harvesting, marketing, and logistics planning. Given that the current algorithm only completes the detection task, further steps are necessary before having a complete solution. Therefore, for future research, images will be captured from tractor platforms, giving a detailed overview of the whole orchard. Plus, with the use of an object tracking algorithm, the detection will be converted into the counting of the fruit load. And with the help of an object volume estimation algorithm, a more detailed description of the crop yield could be achieved by calculating the size of the fruits. Interested to learn more? Don’t hesitate to contact us and discover how intelligent image analysis can support crop management decision making!

/Blog_CORSA_1200x650.png)
/lewis-latham-0huRqQjz81A-unsplash.jpg)
.jpg)